데이터 그룹화를 사용하면 모든 데이터를 논리적 세트로 나눌 수 있으므로 각 그룹에서 별도로 통계 계산을 수행할 수 있습니다.
그룹은 SELECT 연산자의 GROUP BY 문을 사용하여 생성됩니다. 예를 생각해 봅시다.
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
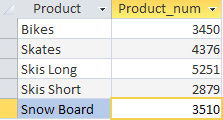
이 요청을 통해 우리는 매월 판매된 제품 수에 대한 정보를 추출했습니다. SELECT 연산자는 두 개의 열 Product(제품 이름)와 Product_num(판매된 제품 수량을 표시하기 위해 생성한 계산 필드)을 출력하도록 명령합니다(필드 수식 SUM(Quantity)). GROUP BY 절은 DBMS에 Product 열을 기준으로 데이터를 그룹화하도록 지시합니다.
테이블의 행을 필터링한 것처럼 그룹화된 데이터를 필터링할 수 있습니다. 이를 위해 SQL에는 HAVING 연산자가 있습니다. 이전 예에 그룹 필터링을 추가해 보겠습니다.
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 4000
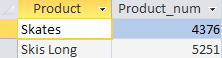
상품별 판매 수량을 계산한 후, DBMS가 판매 수량 4,000개 미만인 상품을 '차단'하는 것을 확인할 수 있습니다.
보시다시피 HAVING 연산자는 WHERE 연산자와 매우 유사하지만 둘 사이에는 중요한 차이점이 있습니다. WHERE은 그룹화하기 전에 데이터를 필터링하고 HAVING은 그룹화한 후에 데이터를 필터링합니다. 따라서 WHERE 절에 의해 제거된 행은 그룹에 포함되지 않습니다. 따라서 WHERE 및 HAVING 연산자를 같은 문장에서 사용할 수 있습니다. 예를 들어보자:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
WHERE Product <> 'Skis Long'
GROUP BY Product
HAVING SUM(Quantity) > 4000
이전 예에 WHERE 연산자를 추가했습니다. 여기서는 제품 "Skis Long"을 지정했으며 이는 차례로 HAVING 연산자에 의한 그룹화에 영향을 미쳤습니다. 그 결과, "스키스 롱" 제품은 판매된 제품이 4,000개 이상인 그룹 목록에 포함되지 않았음을 알 수 있습니다.
일반적인 데이터 샘플링과 마찬가지로 HAVING 연산자를 사용하여 그룹화한 후 그룹을 정렬할 수 있습니다. 이를 위해 이미 익숙한 연산자 ORDER BY을 사용할 수 있습니다. 이 상황에서의 적용은 이전 예제와 유사합니다. 예:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY SUM(Quantity)
또는 정렬하려는 순서대로 필드 번호를 지정하면 됩니다.
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY 2
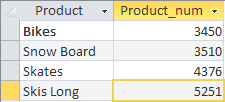
요약 결과를 정렬하려면 HAVING 연산자 뒤에 ORDER BY이 있는 절을 작성하면 됩니다.