이전 섹션에서는 이전에 생성된 테이블에서 데이터를 검색하는 작업을 고려했습니다. 이제 테이블을 생성/삭제하고, 새 레코드를 추가하고, 이전 레코드를 삭제하는 방법을 알아볼 차례입니다.
이러한 목적을 위해 SQL에는 다음과 같은 연산자가 있습니다.
INSERT 연산자를 사용하여 이 연산자 그룹에 대해 알아보겠습니다.
이름에서 알 수 있듯이 INSERT INTO 연산자는 데이터베이스 테이블에 행을 삽입(추가)하는 데 사용됩니다.
추가는 여러 가지 방법으로 수행할 수 있습니다.
따라서 테이블에 새 행을 추가하려면 INSERT INTO table_name(field1, field2 ...) VALUES (value1, value2 ...) 구성. 예를 생각해 봅시다.
INSERT INTO Sellers (ID, Address, City, Seller_name, Country)
VALUES ('6', '1st Street', 'Los Angeles', 'Harry Monroe', 'USA')
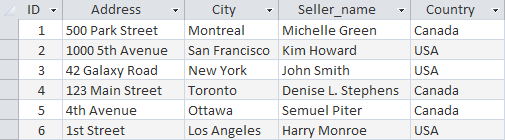
열 이름의 순서도 변경할 수 있지만 동시에 VALUES 매개변수 값의 순서도 변경해야 합니다.
이전 예에서는 INSERT 연산자를 사용할 때 테이블 열의 이름을 명시적으로 지정했습니다. 이 구문을 사용하면 일부 열을 건너뛸 수 있습니다. 이는 일부 열에는 값을 입력하고 다른 열에는 제공하지 않음을 의미합니다. 예:
INSERT INTO Sellers (ID, City, Seller_name)
VALUES ('6', 'Los Angeles', 'Harry Monroe')
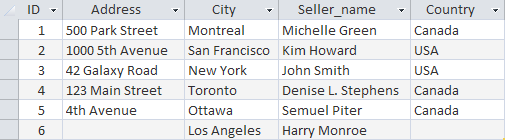
이 예에서는 Address 및 Country 두 열에 대한 값을 지정하지 않았습니다. 테이블을 정의할 수 있는 경우 aaa 문에서 일부 열을 제외할 수 있습니다. 이 경우 다음 조건 중 하나가 충족되어야 합니다. 이 열은 Null 값(값 없음)을 허용하도록 정의되거나 테이블 정의에 기본값이 지정됩니다. 즉, 값을 지정하지 않으면 기본값이 사용됩니다. NULL 값이 해당 행에 표시되는 것을 허용하지 않고 기본 사용에 대해 정의된 값이 없는 테이블에서 열을 생략하는 경우 DBMS는 오류 메시지를 발행하고 행이 추가되지 않습니다.
이전 예에서는 쿼리에 데이터를 수동으로 입력하여 테이블에 데이터를 삽입했습니다. 그러나 INSERT INTO 연산자를 사용하면 다른 테이블의 데이터를 삽입하려는 경우 이 프로세스를 자동화할 수 있습니다. 이를 위해 SQL에는 INSERT INTO ... SELECT ... 과 같은 구성이 있습니다. 이 디자인을 사용하면 한 테이블에서 데이터를 동시에 선택하고 다른 테이블에 삽입할 수 있습니다. 유럽에 있는 우리 제품의 판매자 목록이 포함된 다른 테이블 Sellers_EU가 있고 이를 일반 테이블 Sellers에 추가해야 한다고 가정합니다. 이러한 테이블의 구조는 동일하지만(열 개수 및 이름 동일) 데이터가 다릅니다. 이를 위해 다음 쿼리를 작성할 수 있습니다.
INSERT INTO Sellers (ID, Address, City, Seller_name, Country)
SELECT ID, Address, City, Seller_name, Country
FROM Sellers_EU
내부 키(ID 필드)의 값이 반복되지 않도록 주의할 필요가 있으며, 그렇지 않으면 오류가 발생합니다. SELECT 문에는 데이터를 필터링하기 위한 WHERE 절도 포함될 수 있습니다. 또한 DBMS는 SELECT 연산자에 포함된 열 이름에는 주의를 기울이지 않고 해당 위치의 순서에만 주의를 기울인다는 점에 유의해야 합니다. 따라서 SELECT을 통해 선택된 첫 번째 지정된 열의 데이터는 필드 이름에 관계없이 어떤 경우에도 INSERT INTO 연산자 다음에 지정된 Sellers 테이블의 첫 번째 열에 채워집니다.
데이터베이스 작업을 할 때 백업이나 수정을 위해 테이블의 복사본을 만들어야 하는 경우가 많습니다. SQL에서 테이블의 전체 복사본을 만들기 위해 별도의 연산자 SELECT INTO가 제공됩니다. 예를 들어 Sellers 테이블의 복사본을 생성해야 하며 다음과 같이 쿼리를 작성해야 합니다.
SELECT * INTO Sellers_new
FROM Sellers

이전 구성 INSERT INTO ... SELECT ... 기존 테이블에 데이터를 추가할 때 SELECT ... INTO ... FROM ... 구성은 데이터를 새 테이블에 복사합니다. 첫 번째 구축은 데이터를 가져오고, 두 번째 구축은 데이터를 내보낸다고도 할 수 있습니다.
SELECT ... INTO ... FROM ... 구성을 사용할 때 다음 사항을 고려해야 합니다.