O agrupamento de dados permite dividir todos os dados em conjuntos lógicos, o que possibilita realizar cálculos estatísticos separadamente em cada grupo.
Os grupos são criados usando a instrução GROUP BY do operador SELECT. Vamos considerar um exemplo.
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
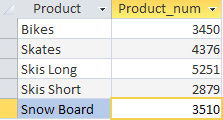
Com essa solicitação extraímos informações sobre a quantidade de produtos vendidos em cada mês. O operador SELECT ordena a saída de duas colunas Produto - o nome do produto e Product_num - o campo calculado que criamos para exibir a quantidade de produtos vendidos (fórmula do campo SUM(Quantity)). A cláusula GROUP BY informa ao DBMS para agrupar os dados pela coluna Produto.
Assim como filtramos as linhas em uma tabela, podemos filtrar dados agrupados. Para isso, existe o operador HAVING no SQL. Vamos pegar o exemplo anterior e adicionar filtragem de grupo.
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 4000
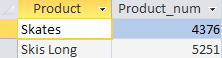
Podemos ver que após o cálculo do número de mercadorias vendidas para cada produto, o SGBD “cortou” os produtos que foram vendidos menos de 4.000 unidades.
Como você pode ver, o operador HAVING é muito semelhante ao operador WHERE, mas há uma diferença significativa entre eles: WHERE filtra os dados antes de serem agrupados e HAVING filtra após o agrupamento. Assim, as linhas que foram removidas pela cláusula WHERE não serão incluídas no grupo. Portanto, os operadores WHERE e HAVING podem ser usados na mesma frase. Considere um exemplo:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
WHERE Product <> 'Skis Long'
GROUP BY Product
HAVING SUM(Quantity) > 4000
Adicionamos o operador WHERE ao exemplo anterior, onde especificamos o produto "Skis Long", que por sua vez afetou o agrupamento pelo operador HAVING. Como resultado, podemos perceber que o produto “Esquis Longos” não entrou na lista de grupos com mais de 4.000 produtos vendidos.
Tal como acontece com a amostragem normal de dados, podemos classificar os grupos após o agrupamento com o operador HAVING. Para isso, podemos usar o já conhecido operador ORDER BY. Nesta situação, a sua aplicação é semelhante aos exemplos anteriores. Exemplo:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY SUM(Quantity)
ou simplesmente especifique o número do campo na ordem em que queremos classificar:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY 2
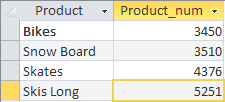
Vemos que para classificar os resultados resumidos, precisamos apenas escrever a cláusula com ORDER BY após o operador HAVING.

