Le regroupement de données vous permet de diviser toutes les données en ensembles logiques, ce qui permet d'effectuer des calculs statistiques séparément dans chaque groupe.
Les groupes sont créés à l'aide de l'instruction GROUP BY de l'opérateur SELECT. Prenons un exemple.
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
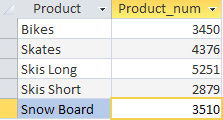
Avec cette demande, nous avons extrait des informations sur le nombre de produits vendus chaque mois. L'opérateur SELECT ordonne d'afficher deux colonnes Product - le nom du produit et Product_num - le champ calculé que nous avons créé pour afficher la quantité de produits vendus (formule de champ SUM(Quantity)). La clause GROUP BY indique au SGBD de regrouper les données par colonne Produit.
Tout comme nous filtrons les lignes d’un tableau, nous pouvons filtrer sur des données groupées. Pour cela, il existe l'opérateur HAVING en SQL. Prenons l'exemple précédent et ajoutons un filtrage de groupe.
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 4000
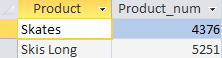
Nous voyons qu'après avoir calculé le nombre de marchandises vendues pour chaque produit, le SGBD "a coupé" les produits vendus à moins de 4 000 unités.
Comme vous pouvez le voir, l'opérateur HAVING est très similaire à l'opérateur WHERE, mais il existe une différence significative entre eux : WHERE filtre les données avant qu'elles ne soient regroupées, et HAVING les filtre après le regroupement. Ainsi, les lignes supprimées par la clause WHERE ne seront pas incluses dans le groupe. Ainsi, les opérateurs WHERE et HAVING peuvent être utilisés dans la même phrase. Prenons un exemple :
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
WHERE Product <> 'Skis Long'
GROUP BY Product
HAVING SUM(Quantity) > 4000
Nous avons ajouté l'opérateur WHERE à l'exemple précédent, où nous avons spécifié le produit "Skis Long", ce qui a à son tour affecté le regroupement par l'opérateur HAVING. De ce fait, on constate que le produit « Skis Longs » ne figure pas dans la liste des groupes comptant plus de 4 000 produits vendus.
Comme pour l'échantillonnage normal des données, nous pouvons trier les groupes après regroupement avec l'opérateur HAVING. Pour cela, nous pouvons utiliser l'opérateur déjà familier ORDER BY. Dans cette situation, son application est similaire aux exemples précédents. Exemple:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY SUM(Quantity)
ou précisez simplement le numéro du champ dans l'ordre dans lequel on souhaite trier :
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY 2
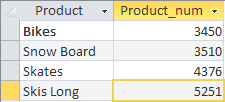
On voit que pour trier les résultats récapitulatifs, il suffit d'écrire la clause avec ORDER BY après l'opérateur HAVING.

