データをグループ化すると、すべてのデータを論理セットに分割できるため、各グループで個別に統計計算を実行できるようになります。
グループは、SELECT 演算子の GROUP BY ステートメントを使用して作成されます。例を考えてみましょう。
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
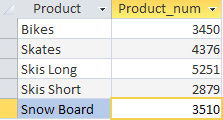
このリクエストにより、各月に販売された製品の数に関する情報を抽出しました。演算子 SELECT は、2 つの列 Product - 製品の名前と Product_num - 販売された製品の数量を表示するために作成した計算フィールド (フィールド式 SUM(Quantity)) を出力するよう命令します。 GROUP BY 句は、Product 列ごとにデータをグループ化するように DBMS に指示します。
テーブル内の行をフィルター処理したのと同じように、グループ化されたデータをフィルター処理できます。このために、SQL には HAVING 演算子があります。前の例を使用して、グループ フィルタリングを追加してみましょう。
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 4000
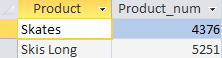
各製品の販売数が計算された後、DBMS は販売数が 4,000 個未満の製品を「除外」したことがわかります。
ご覧のとおり、HAVING 演算子は WHERE 演算子に非常に似ていますが、これらの間には大きな違いがあります。WHERE はグループ化される前にデータをフィルタリングし、HAVING はグループ化後にフィルタリングします。したがって、WHERE 句によって削除された行はグループに含まれません。したがって、WHERE 演算子と HAVING 演算子を同じ文内で使用できます。例を考えてみましょう。
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
WHERE Product <> 'Skis Long'
GROUP BY Product
HAVING SUM(Quantity) > 4000
前の例に WHERE 演算子を追加し、製品「Skis Long」を指定しました。これにより、HAVING 演算子によるグループ化が影響を受けました。その結果、「Skis Long」という製品は、販売数が 4,000 を超えるグループのリストには入っていないことがわかります。
通常のデータ サンプリングと同様に、HAVING 演算子を使用してグループ化した後、グループを並べ替えることができます。このために、すでにおなじみの演算子 ORDER BY を使用できます。この状況では、その適用は前の例と同様です。例:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY SUM(Quantity)
または、単純に並べ替える順序でフィールド番号を指定します。
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY 2
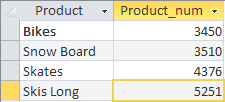
集計結果を並べ替えるには、演算子 HAVING の後に ORDER BY を含む句を記述するだけでよいことがわかります。

