Il raggruppamento dei dati consente di dividere tutti i dati in set logici, il che rende possibile eseguire calcoli statistici separatamente in ciascun gruppo.
I gruppi vengono creati utilizzando l'istruzione GROUP BY dell'operatore SELECT. Consideriamo un esempio.
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
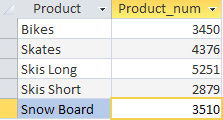
Con questa richiesta abbiamo estratto informazioni sul numero di prodotti venduti in ogni mese. L'operatore SELECT ordina di restituire due colonne Product - il nome del prodotto e Product_num - il campo calcolato che abbiamo creato per visualizzare la quantità di prodotti venduti (formula del campo SUM(Quantity)). La clausola GROUP BY indica al DBMS di raggruppare i dati in base alla colonna Product.
Proprio come abbiamo filtrato le righe in una tabella, possiamo filtrare i dati raggruppati. Per questo esiste l'operatore HAVING in SQL. Prendiamo l'esempio precedente e aggiungiamo il filtro di gruppo.
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 4000
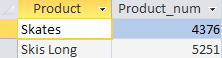
Possiamo vedere che dopo aver calcolato il numero di beni venduti per ciascun prodotto, il DBMS "ha tagliato" quei prodotti che sono stati venduti meno di 4.000 unità.
Come puoi vedere, l'operatore HAVING è molto simile all'operatore WHERE, ma c'è una differenza significativa tra loro: WHERE filtra i dati prima che vengano raggruppati e HAVING filtra dopo il raggruppamento. Pertanto, le righe rimosse dalla clausola WHERE non verranno incluse nel gruppo. Pertanto, gli operatori WHERE e HAVING possono essere utilizzati nella stessa frase. Considera un esempio:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
WHERE Product <> 'Skis Long'
GROUP BY Product
HAVING SUM(Quantity) > 4000
Abbiamo aggiunto l'operatore WHERE all'esempio precedente, dove abbiamo specificato il prodotto "Sci Lunghi", che a sua volta ha influenzato il raggruppamento tramite l'operatore HAVING. Di conseguenza possiamo vedere che il prodotto "Sci Lunghi" non è entrato nell'elenco dei gruppi con più di 4.000 prodotti venduti.
Come con il normale campionamento dei dati, possiamo ordinare i gruppi dopo averli raggruppati con l'operatore HAVING. Per questo possiamo usare l'operatore già familiare ORDER BY. In questa situazione, la sua applicazione è simile agli esempi precedenti. Esempio:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY SUM(Quantity)
o semplicemente specificare il numero del campo nell'ordine in cui vogliamo ordinare:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY 2
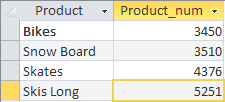
Vediamo che per ordinare i risultati di riepilogo, dobbiamo solo scrivere la clausola con ORDER BY dopo l'operatore HAVING.

