La agrupación de datos le permite dividir todos los datos en conjuntos lógicos, lo que permite realizar cálculos estadísticos por separado en cada grupo.
Los grupos se crean utilizando la instrucción GROUP BY del operador SELECT. Consideremos un ejemplo.
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
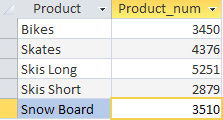
Con esta solicitud extrajimos información sobre la cantidad de productos vendidos en cada mes. El operador SELECT ordena generar dos columnas Producto: el nombre del producto y Product_num: el campo calculado que creamos para mostrar la cantidad de productos vendidos (fórmula de campo SUM(Quantity)). La cláusula GROUP BY le dice al DBMS que agrupe los datos por la columna Producto.
Así como filtramos filas en una tabla, podemos filtrar según datos agrupados. Para ello existe el operador HAVING en SQL. Tomemos el ejemplo anterior y agreguemos filtrado de grupo.
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 4000
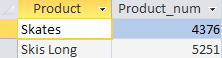
Vemos que después de calcular el número de productos vendidos para cada producto, el DBMS "cortó" aquellos productos de los que se vendieron menos de 4.000 unidades.
Como puede ver, el operador HAVING es muy similar al operador WHERE, pero hay una diferencia significativa entre ellos: WHERE filtra los datos antes de agruparlos y HAVING filtra después de agruparlos. Por lo tanto, las filas eliminadas por la cláusula WHERE no se incluirán en el grupo. Entonces, los operadores WHERE y HAVING se pueden usar en la misma oración. Considere un ejemplo:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
WHERE Product <> 'Skis Long'
GROUP BY Product
HAVING SUM(Quantity) > 4000
Agregamos el operador WHERE al ejemplo anterior, donde especificamos el producto "Esquíes largos", lo que a su vez afectó la agrupación por el operador HAVING. Como resultado, podemos ver que el producto "Esquíes largos" no figura en la lista de grupos con más de 4.000 productos vendidos.
Al igual que con el muestreo de datos normal, podemos ordenar los grupos después de agruparlos con el operador HAVING. Para ello podemos utilizar el ya conocido operador ORDER BY. En esta situación, su aplicación es similar a los ejemplos anteriores. Ejemplo:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY SUM(Quantity)
o simplemente especificar el número de campo en el orden en el que queremos ordenar:
Run SQLSELECT Product, SUM(Quantity) AS Product_num
FROM Sumproduct
GROUP BY Product
HAVING SUM(Quantity) > 3000
ORDER BY 2
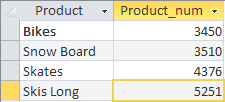
Vemos que para ordenar los resultados resumidos, solo necesitamos escribir la cláusula con ORDER BY después del operador HAVING.

